性能提升40% 阿里开源千问3向量模型
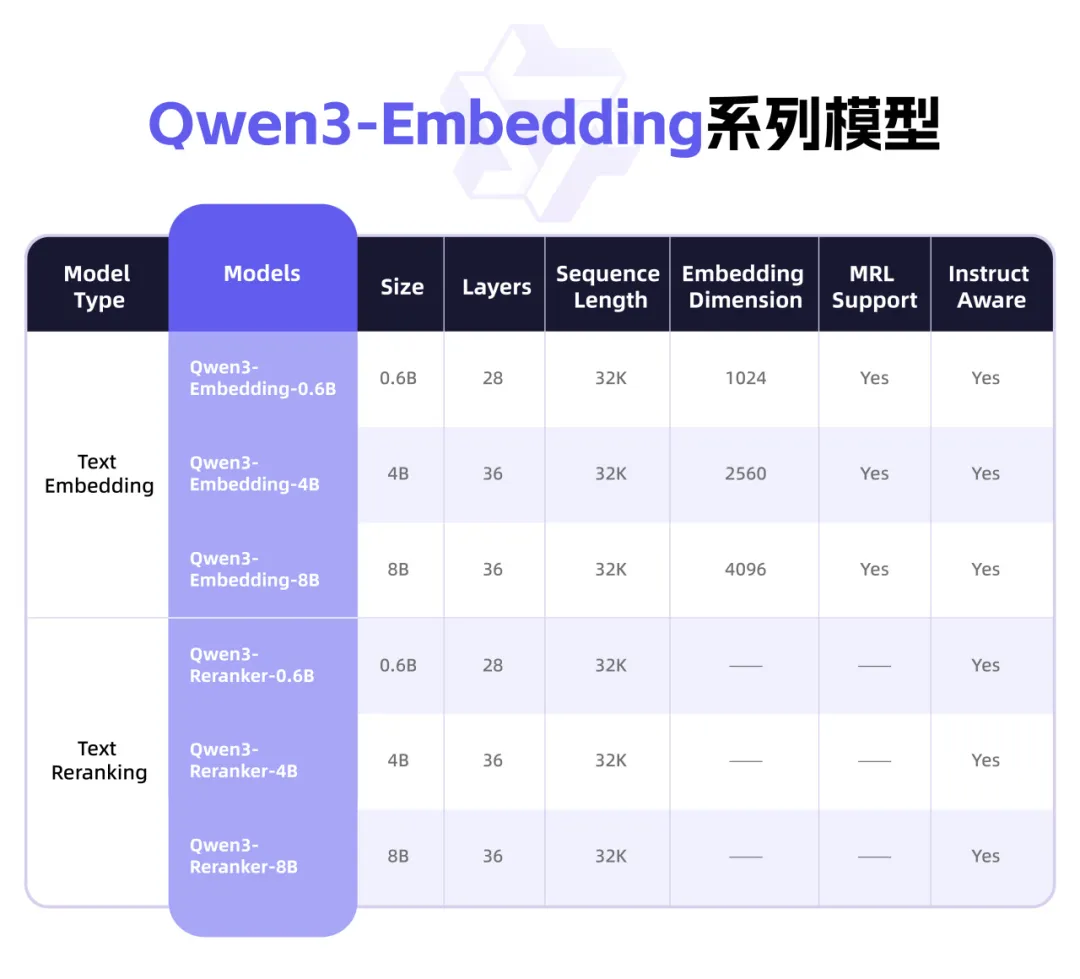
Qwen3-Embedding 系列模型
向量模型像是AI的“翻译器”,它可以将文本、图片等人类可认知的非结构化信息,映射到机器更易理解的向量空间,再基于这些向量实现高效的信息分类、检索或排序。也正因此,向量模型对于提升AI的语义理解、信息检索、多模态融合等核心能力至关重要。基于千问3模型,通义团队通过对比训练、SFT、模型融合等方法,打造出全新的千问3向量模型,包含文本嵌入模型 Qwen3-Embedding以及文本排序模型Qwen3-Reranker。
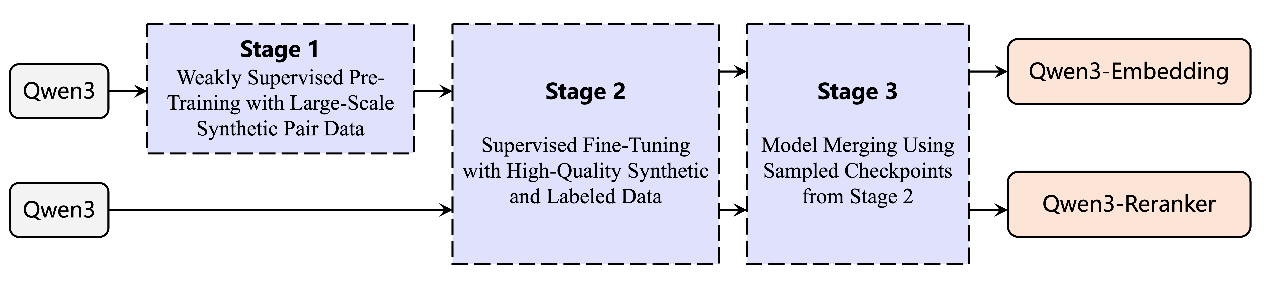
千问3向量模型系列训练过程图
相较于上一个版本,千问3向量模型在文本检索、聚类、分类等核心任务上提升最高40%以上的性能。同时,得益于千问3的多语言能力,千问3向量模型系列率先支持超100种语言,并涵盖多种编程语言,可实现强大的多语言、跨语言及代码检索能力。
为方便开发者,此次有9款千问3向量模型开源,涵盖0.6B、4B、8B等不同尺寸及GGUF版本。开发者可从中找到最符合需求的模型,自由组合模块,还可自定义向量或指令,实现特定任务、语言和场景的深度优化。比如,开发者可在智能搜索、推荐系统中采用Qwen3-Embedding作文本向量化,或者在RAG实践中用Qwen3-Reranker提升最终结果的相关性和准确性,甚至与视觉理解模型结合,探索前沿的跨模态语义理解。
目前,千问3 Embedding和Reranker模型均已在魔搭社区、Hugging Face和GitHub等平台上开源,开发者也可直接通过阿里云百炼使用API服务。
关键词:
免责声明:本网站内容主要来自原创、合作媒体供稿和第三方自媒体作者投稿,凡在本网站出现的信息,均仅供参考。本网站将尽力确保所提供信息的准确性及可靠性,但不保证有关资料的准确性及可靠性,读者在使用前请进一步核实,并对任何自主决定的行为负责。本网站对有关资料所引致的错误、不确或遗漏,概不负任何法律责任。任何单位或个人认为本网站中的网页或链接内容可能涉嫌侵犯其知识产权或存在不实内容时,应及时向本网站提出书面权利通知或不实情况说明,并提供身份证明、权属证明及详细侵权或不实情况证明。本网站在收到上述法律文件后,将会依法尽快联系相关文章源头核实,沟通删除相关内容或断开相关链接。

科技排行榜
-
2023-07-03 11:30
-
2023-07-03 13:26
-
2023-07-03 13:38
-
2023-07-03 13:58
-
2023-07-03 14:25
科技热门推荐
-
2023-07-03 11:30
-
2023-07-03 13:26
-
2023-07-03 13:38
-
2023-07-03 13:58
-
2023-07-03 14:25







